
Entertainment & Media
5 min read
6 Benefits of Real-Time Voice Cloning
Join the over 2,000,000 users who love LOVO AI. Our award-winning voice generator and text to speech software is packed with 500+ voices in 100 languages. Create engaging videos with voice for marketing, training, social media, and more!
Start now for free

Chloe Woods
English Female

Sophia Butler
English Female

Santa Clause
English Male

Katelyn Harrison
English Female

Bryan Lee Jr.
English Male

Thomas Coleman
English Male
2,000,000+
Trusted by professionals & creatives globally
Experience unparalleled voiceover production with our voice generator and online video editor, featuring professional grade human-like voices and powerful editing tools.
Surprise your audience with the perfect AI voice in 100+ languages for your content.
For all your voiceover and video needs - scripts, ultra-realistic voices, images, editing and more! Genny has all the features you need to create engaging videos with integrated AI features.
Using Genny removes the need to spend time and money to record or use expensive equipment to achieve professional voiceovers with our advanced voice generator.
Text To Speech

Achieve perfect synchronization without sacrificing speed or accuracy. With Genny’s online video editor, you can edit content effortlessly to create engaging high-quality videos.
Online Video Editor

Globalize your content and boost engagement in 20+ languages with our auto subtitle generator. Customize, animate, and transform your video with just a few clicks.
Auto Subtitle Generator
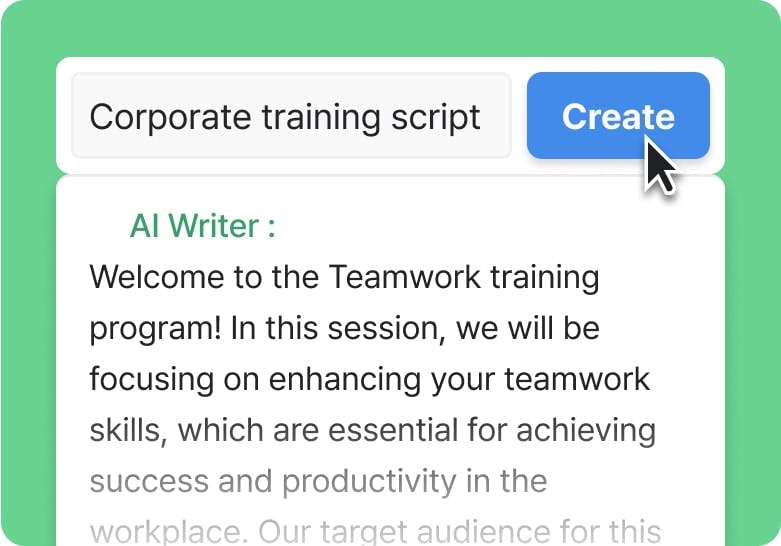
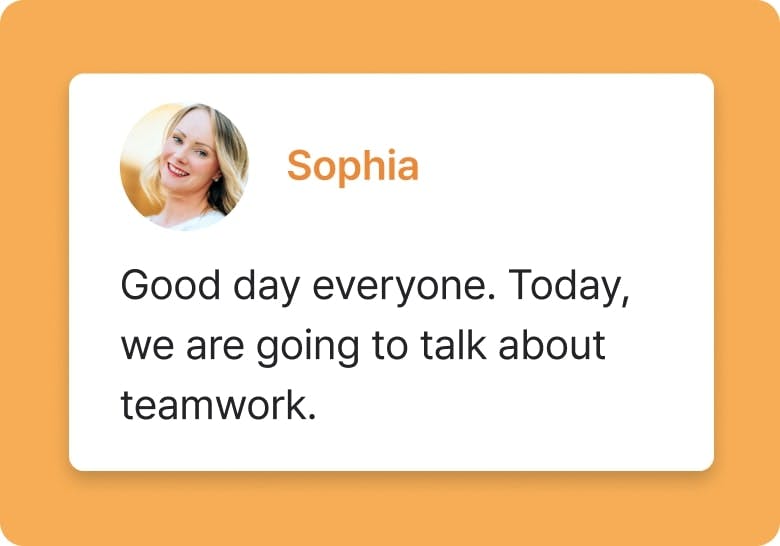
Writer's block is everyone's nightmare. Genny's AI writer can help you get started on your script quickly by generating professionally written content in a lightening fast.
AI Writer

Genny’s voice cloning lets you instantly create custom voices with just one minute of audio. Give your brand a unique voice that sets your content apart from the crowd.
Voice Cloning

No more spending hours searching the web for the perfect stock image. Generate HD royalty-free images and add them to your videos in seconds with Genny’s AI art generator.
AI Art Generator
Drive efficiency and collaborate creatively with Genny teams and keep your projects safely secured with our cloud storage so you and your team can access them at any time!
Learn About Genny Teams
With our easy to use API, you now have the power to use the most advanced AI voices in the world in your own app or service! Get started in as little as 5 lines of code.
LOVO Open API
Discover all kinds of content LOVO can help you create instantly with tailored AI Voices.
Unlock your creative potential
Try Genny for free
No Credit Card required
14-day trial of pro
If you cannot find an answer, email hello@lovo.ai for help.
Start now for free
LOVO is the most advanced AI voice and text-to-speech generator available on the market. With LOVO, you can save thousands of dollars and hours of time in generating realistic and high-quality voiceovers. Our cutting-edge technology produces super realistic voices that are almost impossible to distinguish from real human voices. Our easy-to-use professional UI makes generating voiceovers effortless, even for those with no prior experience in audio production. LOVO is perfect for businesses, content creators, educators, and anyone looking to create engaging content that stands out from the crowd. LOVO is designed to streamline your content creation process so you can focus on what matters most - delivering your message to your audience. With LOVO, you have access to an extensive library of voices, languages, and accents, ensuring that you find the perfect voice to match your brand or project.
With AI now more accessible than ever, tools like text-to-speech generators are the perfect assistant for content creation. These tools save you time and money by removing the need for expensive equipment or time-consuming tasks such as recording and editing while providing high-quality audio with realistic human voices.
At LOVO, our team has focused on creating Genny, the most advanced voice generator that produces high-quality voiceovers to elevate your video and audio projects. Complete the final stages of your project with Genny by generating your voiceover and seamlessly syncing it with your video. Then, before exporting your video, add all the finishing touches for a truly professional look, such as subtitles, images, logos, and video clips.
Genny is designed to allow anyone to get started immediately - no downloading software or complicated onboarding or learning is required. Simply sign in with your web browser and you are good to go! Our intuitive and easy-to-use UI makes it a breeze for anyone who needs to create content up and running in minutes. This means you can focus on what matters most - engaging and delivering your message to your audience.
Genny supports Text to Speech in:


